全文檢索筆記 - Lucene.Net (2) 盤古分詞
| | | 0 | |
前一篇筆記談完 Lucene.Net 術語與基本觀念,感覺用盤古中文分詞器是不錯的主意。先來個最簡單的「盤古中文分詞->建立索引->查詢關鍵字」 Lucene.Net 範例:
private static string IndexPath = "E:\\LuceneIndex";
public static void SimpleDemo()
{ //指定索引資料儲存目錄 var fsDir = FSDirectory.Open(IndexPath);
//建立IndexWriter using (var idxWriter = new IndexWriter(
fsDir, //儲存目錄 new PanGuAnalyzer(), //使用盤古分詞器
true, //清除原有索引,重新建立
IndexWriter.MaxFieldLength.UNLIMITED //不限定欄位內容長度 ))
{ //示範為兩份文件建立索引 var doc = new Document(); //每份文件有兩個Field: Source、Word doc.Add(new Field("Source", "阿甘正傳", Field.Store.YES, Field.Index.ANALYZED));
doc.Add(new Field("Word", "人生就像一盒巧克力,你永遠也不會知道你將拿到什麼。",
Field.Store.YES, Field.Index.ANALYZED));
idxWriter.AddDocument(doc);
doc = new Document(); doc.Add(new Field("Source", "Spider Man", Field.Store.YES, Field.Index.ANALYZED));
doc.Add(new Field("Word", "Remember, with great power, comes great responsibility.",
Field.Store.YES,
Field.Index.ANALYZED));
idxWriter.AddDocument(doc);
//建立索引 idxWriter.Commit();
idxWriter.Optimize();
}
//查詢示範 //若不需刪除文件或修改Norms,第二個參數傳入true採唯讀方式效能較好 var searcher = new IndexSearcher(fsDir, true);
//指定欄位名傳入參數 QueryParser qp = new QueryParser(Version.LUCENE_30, "Word", new PanGuAnalyzer());
Query q = qp.Parse("巧克力"); var hits = searcher.Search(q, 10); //查詢前10筆 Debug.WriteLine($"找到{hits.TotalHits}筆"); foreach (var doc in hits.ScoreDocs)
{ Debug.WriteLine($"{searcher.Doc(doc.Doc).Get("Word")}");
}
}
使用盤古分詞器建立索引,試著查詢「巧克力」,不孚眾望,真的找到了!
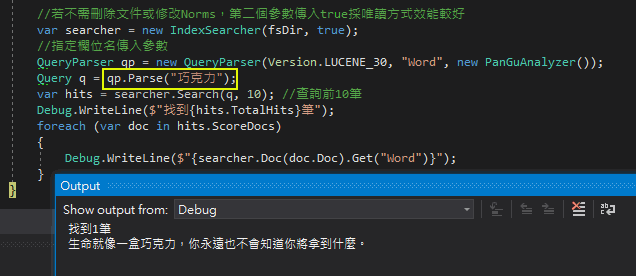
不過再多試幾下,就被澆了冷水。改查詢"永遠"... 登楞! 找不到。
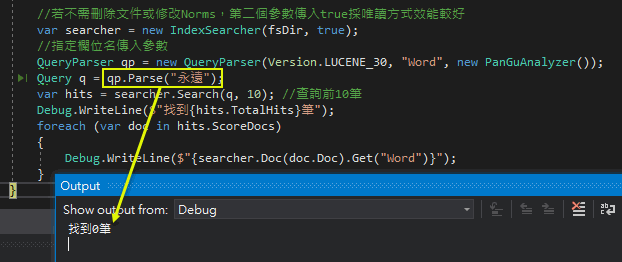
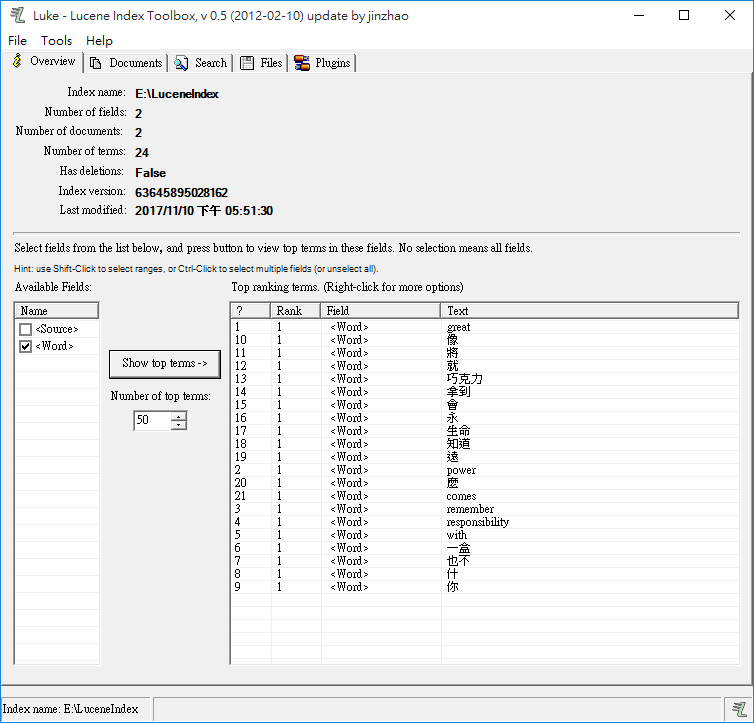
分詞搜尋跟傳統印象中 Word/Excel/Notepad 尋找不太相同。分詞器會將整段文字分成一個個 Term,"永"、"遠"、跟 "永遠" 是不同的東西,使用 Luke.Net 觀察建立的索引,盤古分詞的真實分詞結果如下。永遠被拆成了永跟遠,而查詢「永遠」PanGuAnalyzer 會判定沒有相符合內容。
用盤古分詞再多做了一些測試:
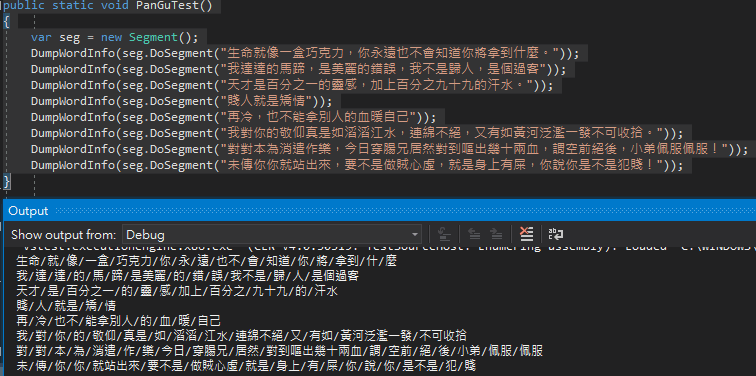
有些詞被拆成單字或斷錯位置,預期如果直接查詢"永遠"、"什麼"、"不會"、"馬蹄"、"收拾"、"賤人"、"百分之九十九"等詞將不會得到符合的結果:
生命/就/像/一盒/巧克力/你/永/遠/也不/會/知道/你/將/拿到/什/麼
我/達/達/的/馬/蹄/是美麗/的/錯/誤/我不是/歸/人/是個過客
天才/是/百分之一/的/靈/感/加上/百分之/九十九/的/汗水
賤/人/就是/矯/情
再/冷/也不/能拿別人/的/血/暖/自己
我/對/你/的/敬仰/真是/如/滔滔/江水/連綿不絕/又/有如/黃河泛濫一發/不可收拾
對/對/本/為/消遣/作/樂/今日/穿腸兄/居然/對到嘔出幾十兩血/謂/空前/絕/後/小弟/佩服/佩服
未/傳/你/你/就站出來/要不是/做賊心虛/就是/身上/有/屎/你/說/你/是不是/犯/賤
由此可知,中文分詞器決定"查詢效率與準確性",愈是精準將文字解析成單字,索引檔愈小,愈能快速查到正確結果。英文有空白,很容易精確切割詞與詞,將沒有標點的連續中文正確切成詞彙明顯難上許多。字典檔是找出詞彙的捷徑,但仍存在白痴造句法陷阱,例如: 這書本來就不是給小孩、啤酒不如果汁好喝。由於難以 100% 掌握字句原意,有些分詞器會透過針對同一段文字列舉不同組合提高命中率(多元分詞,或稱為最細粒度分詞),例如: 我是程式設計師,拆解成: 我/是/程式/程式設計/設計師/程式設計師。另一個思考方向是乾脆將文字拆成單字或較小的詞彙,例如: 我/是/程/式/設/計/師,查詢「程式設計」相當於找尋同時出現 程/式/設/計 四個詞彙,但如此查詢效能勢必要打折扣。
我找到一個替代做法在這個盤古分詞範例中查到「永遠」- 用 PhraseQuery 拼裝多個字元:
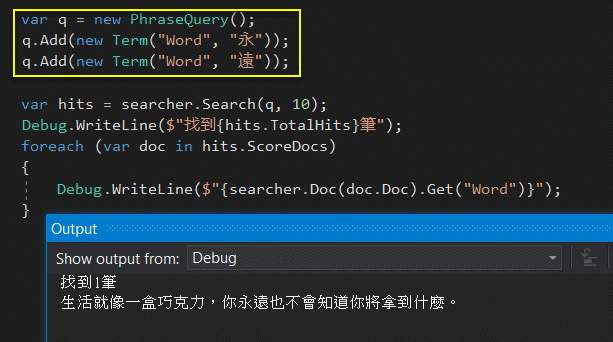
不過,用這招查詢 "永" "遠" "也" 會失敗,原因是分詞結果中的 Term 是 "也不","也" 比對不符! 除非字典檔夠完整,能讓盤古分詞產生更理想的結果,遇到分詞不正確或被拆成單詞都會導致查不到預期結果。(也可能我錯過什麼簡便做法,懇請十方大德賜教)
在盤古分詞器踩到一些坑之後,我回頭改用 Lucene.Net 內附的 StandardAnalyzer,結果好多了! 只要文字相連,就可以查到,不管關鍵字是否為有意義(例如: 「到什」),其邏輯接近 LIKE '%關鍵字%',但預期搜尋效能不如字彙分詞。至於跳幾個字組裝出的「永不知」及順序顛倒的「力巧克」則如預期沒有吻合項目。
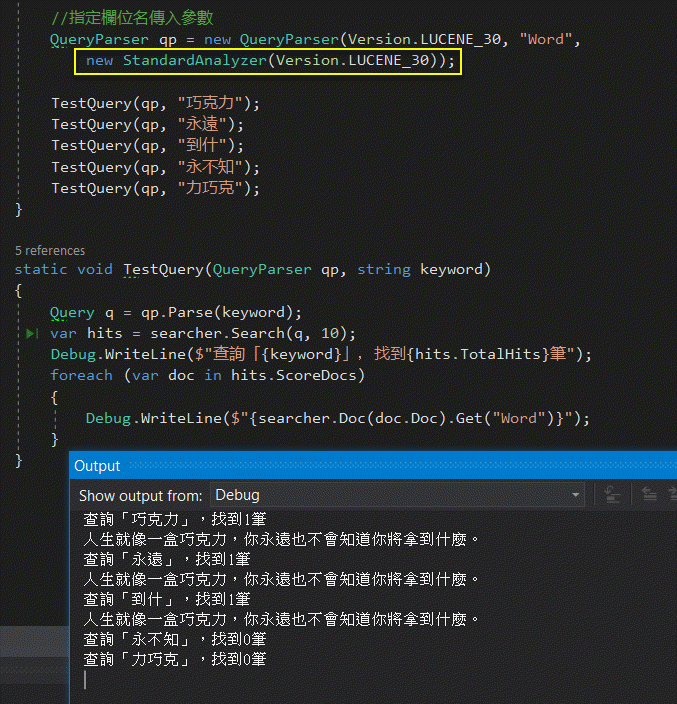
經過以上簡單測試,若不考慮效能跟索引空間,看起來 StandardAnalyzer 比盤古分詞簡單可靠,滿足最基本的全文檢索要求,算是已立於不敗之地,確認用 Lucene.Net 不致開天窗。至於中文分詞器的運作細節,就留待下篇筆記再來探討。
Comments
Be the first to post a comment