全文檢索筆記 - Lucene.Net (1)
| | | 2 | |
網站專案的規格提到了網站內容的全文檢索,不要求比美 Google 的速度與精準度,提供最基本的關鍵字查詢就成。陸續評估了一些解決方案,整理成筆記備忘兼分享。
談到在 .NET 做全文檢索,不能不提 Lucene.Net 這個開源全文檢索引擎!
如果你對 Lucene.Net 很陌生,推薦 CSDN 有篇不錯的入門指引: 使用Lucene.Net实现全文检索。
剛開始接觸 Lucene.Net 被一堆術語搞得昏頭轉向,尤其是建立索引欄位時,參數裡有一堆 ANALYZE、NORMS、POSITION、OFFSETS,搞得我一頭霧水。以下整理使用 Lucene 程式庫時可能用到的一些術語:
-
Document 文件
文件是一堆欄位( Field )的集合,也搜索結果項目的基本單位,一般會對應到實際的文件、檔案、網頁... 等。 -
Filed 欄位
可分為四類: 參考
1. Keyword – 不分析但要建立索引,例如: URL、檔案路徑、人名、身分證號、電話號碼… 等。
2. Unindexed – 不分析也不建索引,呈現結果時一併顯示,但不作為查詢條件。
3. UnStored –分析並建索引但不保存,可當成查詢條件,但不需出現在查詢結果,例如: 文件內容。
4. Text - 分析、建索引且保存完整內容可顯示於查詢結果。 -
Term 詞彙
搜尋條件的基本單位,包含欄位名稱及關鍵字內容。分詞器解析文字內容拆成一個個 Term,搜索時透過 Term 比對才能快速找到目標,分析出的 Term 會儲存於索引檔方便日後查詢。 -
Analyzer 分析器/分詞器
分詞器負責將文字內容拆解成一個個 Term 以建立索引,搜索時以 Term 為對象遠比 LIKE '%...%' 有效率(Index Seek vs Index Scan)。分詞過程是先將文字內容單元化(Tokenization),提取出 Token 後結合欄位名稱形成 Term。參考 -
常見中文分詞器
WhitespaceAnalyzer 只去除空白,不支援中文
SimpleAnalyzer 去除字母以外的符號,不支援中文
StopAnalyzer 比 SimpleAnalyzer 再多去除 the, a, this 等虛詞,不支援中文。
StandardAnalyzer 英文部分比照 StopAnalyzer,但支援中文單字切割,每個中文字元一個 Term。
CJKAnalyzer 支援中日韓文字,但中文支援不理想。
SmartChineseAnalyzer 比較標準的中文分詞,但效果也不是很好。
PanGuAnalyzer 盤古分詞器,專為中文研發,有字典檔提高準確度。可用 NuGet 安裝,是蠻流行的中文分詞器。參考1 參考2
MMSeg 也可用 NuGet 直接安裝,以演算法為核心,快速且簡單,但準確率不如盤古。
IKAnalyzer 中國研發,頗熱門且持續在發展的分詞器,效果看起來很少,但 .NET 版本難尋(Github 有一些棄守的 .NET 版半成品,大陸網站找到的下載連結多已失效,唯一找到的 DLL 版來自 2008 年相容性存疑,放棄未試) -
Boost 是什麼?
簡單地說,Boost 是賦與欄位不同權重讓查詢結果更符合預期的機制,可想像成 Google 搜索關鍵字時決定那一筆優先顯示的邏輯,Lucene 透過 Boost 決定查詢結果符合度。
Boost 可以當名詞用,例如 Document Boost、Field Boost、Query Boost,是一個浮點數,可用於查詢結果排序。預設值為1.0,再乘上多個因子得到最後結果,數字愈大代表愈相關愈重要。Lucence 查詢過程包含布林符合比對以及排序分數計算,Boost 用於排序比分階段。
Boost 當動詞用時意指增加某個項目的 Boost 值,例如 Boost 某個 Field 代表增加該欄位的 Boost 值,Boost 某個 Documentd 代表增加該文件的 Boost 值。
當我們對預設的查詢結果不滿意,便可透過 Boost 某個欄位或文件讓結果符合預期。
例如: 我們可以將標題欄位的權重設定比內文欄位高,如此,標題包含關鍵字與內文包含關鍵字相比,標題有關鍵字應視為更符合查詢條件,我們可以 Boost 標題欄位,使其優先顯示在查詢結果中。Field.SetBoost()可設定Boost值。
Boost 分為 Index Time Boost 及Query Time Boost。Index Time Boost 指在建立索引時就計算好欄位或文件的 Boost 值。Query Time Boost 則是查詢時賦與搜尋條件不同的 Boost 值以影響顯示結果。 參考 -
Norms 是什麼?
Norms 是 Index Time Boost 保存 Boost 因子的方法,在建立索引階段產生 Boost 數字儲存下來。Norms 的計算依據是欄位內容長短,符合條件且字數愈少的結果愈優先。
建立索引時啟用 Norms 會耗用一些運算並佔用每個欄位 1 Byte 的空間,如不需要可停用它以省效能。 參考
要了解上述術語的原因是我們在建立 Field 時有一堆參數要指定,初上手常會搞不清楚該怎麼設定,即使讀了參數說明文件若不懂 NORMS、POSITION、OFFSET 等術語還是不知如何下手,以下做個簡單整理:
public Field(string name, string value, Field.Store store, Field.Index index, Field.TermVector termVector);
- Field.Store
- YES 或 NO。
當文字內容很長且不需顯示在查詢結果中,可選擇不存文字本體只留索引以節省空間。 - Field.Index
- ANALYZED - 建立索引並分詞(適用內文、標題、摘要等)
- NOT_ANALYZED - 索引但不分詞,使用 NORMS
- ANALYZED_NO_NORMS - 索引並分詞,不使用NORMS
- NOT_ANALYZED_NO_NORMS - 索引不分詞且不用NORMS
- NOT - 不索引
- Field.TermVector 參考 Position 與 Offset 差異
- YES - 統計詞彙(Term)出現頻率
- WITH_POSITIONS - 統計頻率,記錄出現位置(以詞彙為單位)
- WITH_OFFSETS - 統計頻率,記錄起迄字元位置
- WITH_POSITIONS_OFFSETS - 統計頻率,記錄出現位置及起迄字元位置
- NO - 完全不統計
文章一開始提到的介紹文針對不同應用整理了簡單的欄位參數建議:
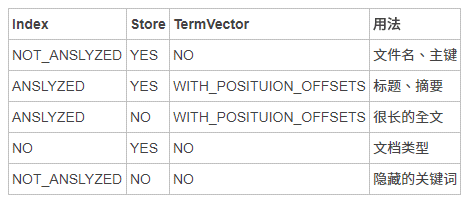
結論
Lucene.Net 提供很高的擴充空間與客製彈性,嚴格來說一個框架而非完整解決方案,開發者可以自行調整權重、索引邏輯,滿足各式刁鑽需求。由其運作原理,中文文件的分詞將是搜尋結果符合預期與否的關鍵,盤古分詞器很簡便易用,但既有的分詞及查詢結果離一般對中文檢索期待仍有距離,評估要投入不少的時間優化改善,值不值投資見仁見智,下篇文章再進一步闡述。
Comments
# by sholfen
它的一個很大的問題是,超級久沒更新了......
# by 阿光
2024/10/29 他有新版了,支援.NET 8.0