SQL筆記:再談動態WHERE條件
| | | 2 | |
前一篇文章探討了「WHERE 1=1動態查詢條件組裝」的效能問題,並介紹如何利用C#語言特性簡單寫出沒有多餘WHERE 1=1的馬甲線SQL指令。而在前文提到的Code Review會議,還有一招不需要組裝WHERE指令的做法也被提及。
//REF: http://goo.gl/SBF1Wi by 91 /// <summary> /// 當資料物件為null時傳回DBNull.Value /// </summary> /// <param name="obj"></param> /// <param name="convEmpty">空字串是否也要傳DBNull.Value</param> /// <returns></returns> public static object NullToDBNullValue(this object obj, bool convEmpty = false)
{ if (convEmpty && obj != null &&
obj is string && string.IsNullOrEmpty((string)obj))
{ return DBNull.Value; }
return obj ?? DBNull.Value; }
static void DynaWhereSample2(DateTime? date, string catg, string keywd)
{ SqlCommand cmd = new SqlCommand(); cmd.CommandText = @" SELECT * FROM MyTable
WHERE
(@date IS NULL OR Date = @date) AND
(@catg IS NULL OR Catg = @catg) AND
(@keywd IS NULL OR Subject LIKE '%' + @keywd + '%')";
cmd.Parameters.Add("@date", SqlDbType.DateTime).Value = date.NullToDBNullValue();
cmd.Parameters.Add("@catg", SqlDbType.VarChar).Value = catg.NullToDBNullValue(true); cmd.Parameters.Add("@keywd", SqlDbType.NVarChar).Value = keywd.NullToDBNullValue(true); //執行SQL,以下省略 }
如上範例,不管使用者是否填寫限制條件都一律傳入參數,若使用者未填值,參數值設為NULL,透過(@catg IS NULL OR Catg = @catg) 實現「@catg不是NULL時執行比對,否則就不設限制」的效果。程式中有一眉角,SqlParameter要設成NULL較嚴謹的做法是傳入DBNull.Value,我參考了91的做法,利用Extension Method統一轉換,並增設將String.Empty也轉成DBNull.Value的選項。
這麼寫的好處是SQL指令從頭到尾固定,可節去重新編譯SQL指令的效能損耗,另外,少了依參數值決定是否串接AND條件的繁瑣邏輯,程式碼看來清爽許多,感覺是個簡潔又有效率的好做法。但事實真是如此?學會判別執行計劃優劣後,我們學會用更精確的角度衡量SQL指令效能。
依我的直覺,面對 (@catg IS NULL OR Catg = @catg) ,SQL應該會比照WHERE 1=1,聰明地略過永遠成立或永遠不成立的部分,選擇適合的執行計劃。
不過,實測結果顯然與想像有出入:(第一列的dbcc freeproccache指令用來清除執行計劃快取,確保SQL依本次傳入參數進行最佳化)
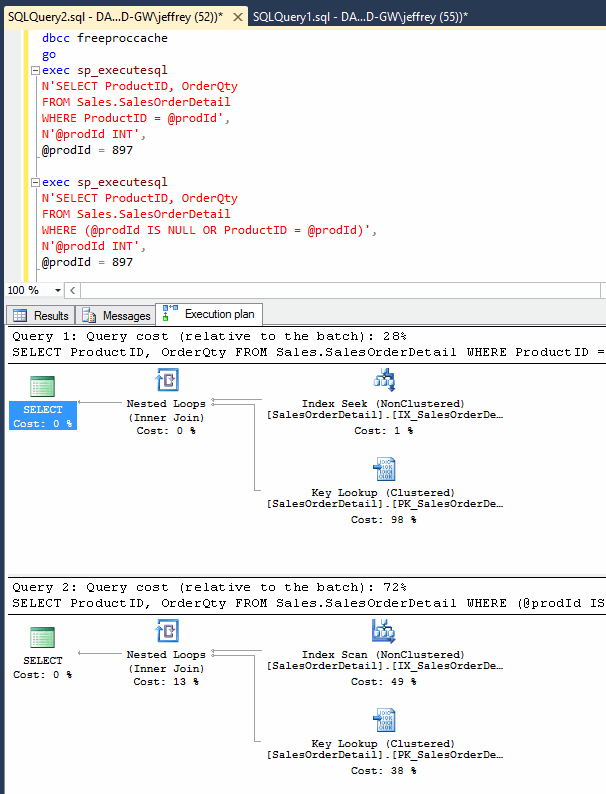
如圖所示,WHERE (@prodId IS NULL OR ProductID = @prodId) 在結果只有兩筆的情況下,仍選擇使用Index Scan,而且不是Clustered Index Scan,而且是Index Scan加Key Lookup,意味@prodID IS NULL確實影響SQL對執行計劃的選擇。
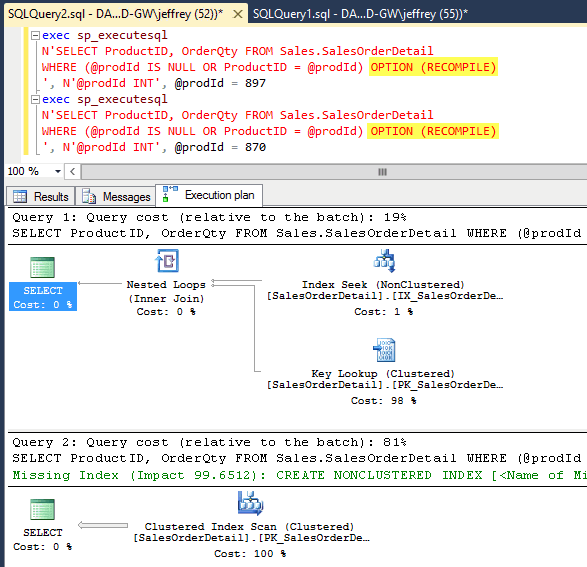
試著加上OPTION (RECOMPILE),強迫每次執行重新編譯SQL,測試結果才貼近我們期望的最佳化(筆數少 Index Seek+Key Lookup,筆數多Index Scan),但如此也喪失原本想節省重新編譯程序的優勢。
再延伸一個更複雜的案例,我們在查詢摻入子查詢,當@prodId與@qty均為NULL時,SQL理應不要理會SpecialOfferID及OrderQty比對,用Clustered Index Scan就好。
SELECT ProductId, OrderQty FROM Sales.SalesOrderDetail WHERE
(@prodID IS NULL OR SpecialOfferID IN
(SELECT SpecialOfferID FROM Sales.SpecialOfferProduct
WHERE ProductId = @prodId)) AND (@qty IS NULL OR OrderQty > @qty)
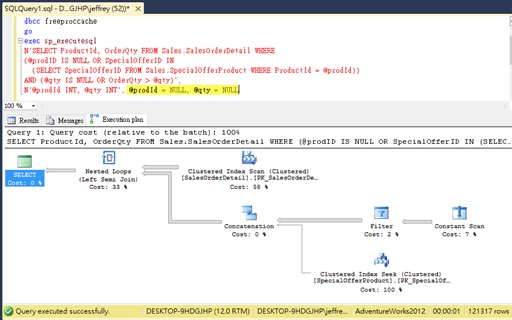
實測結果讓人意外,即使已知@prodId及@qty為NULL,SQL在執行計劃裡仍納入OR後方的子查詢!
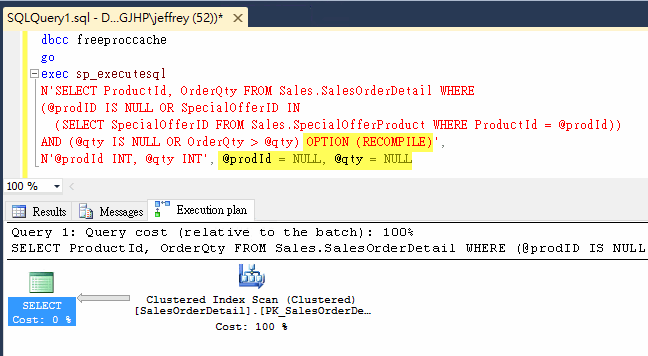
一樣得加上OPTION (RECOMPILE)才會導回我們期望的最佳化結果-Clustered Index Scan。
看到這裡,大家是否覺得SQL好笨?其實不然,我們得從另一個角度思考,當未指定OPTION (RECOMPILE),編譯SQL產生的執行計劃將會被Cache並用在後續的查詢,故SQL必須準備一個不管參數為何都能適用的執行計劃。若因第一次參數傳NULL,就將只做Index Scan不含子查詢的執行計劃寫入Cache,之後傳入的參數有值需要子查詢,豈不開天窗?因此,SQL在策略上必須基於「所有參數都有值」的假設決定執行計劃,才能確保不管參數為何都能順利執行,可以想見,這種(@p1 IS NULL OR P1 = @p1) AND (@p2 IS NULL OR P2 = @p2) 的SQL指令,將會假設@p1與@p2都有值決定執行計劃。
由此看來,「SQL指令固定靠參數是否為NULL動態切換條件」的做法,必須每次重新編譯SQL(加上OPTION (RECOMPILE))才避免套用以最複雜條件為前題的執行計劃,但如此又無法藉重覆利用執行計劃提升效能,整體評估後,還是前篇介紹的串接WHERE的做法略勝一籌。
Comments
# by mis2000lab
謝謝分享 :-) 您提到的,很類似 SqlDataSource(勾選"開放式並行存取"選項後)預設產生的SQL指令。 例如 WHERE ... (([A] = @original_title) OR ([A] IS NULL AND @original_A IS NULL)) AND... 以後對於這些預設產生的SQL指令得更加小心
# by wALTER
謝謝黑大分享這一篇跟前一篇, 受益良多 :) 多年前打架打輸DBA所以被迫存取DB一律要透過stored procedure 所以我們只能用"@catg IS NULL"這招苟且偷生了 😂