【茶包射手日記】勿用UrlEncodeUnicode/escape
 |  | 0 |  | 10,508 |  |
寫WebClient.DownloadString()時用了"some.aspx?t=" + HttpUtility.UrlEncodeUnicode("中文")寫法組網址及Query String參,遇到一些問題,學到一些知識,筆記之。
先來個範例好說明。為便於測試,我寫了一個超簡單的ChkQueryString.aspx傳回Request.Url.Query檢查URL查詢參數:
<%@ Page Language="C#"%> <% Response.Write("QueryString=" + Request.Url.Query); %>
分別嘗試三種不同組裝中文查詢參數URL的做法,HttpUtility.UrlEncodeUnicode()、HttpUtility.UrlEncode()以及直接寫中文不編碼:
static void Test2()
{ WebClient wc = new WebClient();
var testUrl = "httq://localhost:30055/ChkQueryString.aspx";
Debug.WriteLine(wc.DownloadString(
testUrl + "?t=" + HttpUtility.UrlEncodeUnicode("測試"))); Debug.WriteLine(wc.DownloadString(
testUrl + "?t=" + HttpUtility.UrlEncode("測試"))); Debug.WriteLine(wc.DownloadString(
testUrl + "?t=測試"));
}
執行結果如下:
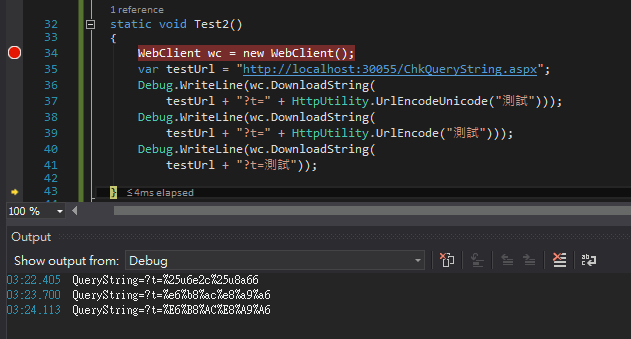
UrlEncode()與直接寫中文的結果相同,都是轉為"測試"二字的UTF-8編碼,共六個Byte的ASCII碼(%xx),但UrlEncode()的16進位數字為小寫,寫中文交給DownloadString()轉碼的十六進位數字則為大寫。UrlEncodeUnicode()轉碼結果為%unnnn格式,但經過DownloadString()時又被轉了一次變成%25uxxxx(「%」被換成%25),多重轉碼造成參數在Server端無法正確還原。
為什麼DownloadString()可以正確處理UrlEncode()甚至原始的中文參數,處理%unnnn格式時確會出錯呢?
經過一番調查,得到一個結論:
UrlEncodeUnicode()包含Unicode字樣,貌似更先進,卻是過時的產物!勿用!
在MSDN文件上,UrlEncodeUnicode()被標示為「注意:此 API 現在已經過時。/ Note: This API is now obsolete.」,理由是UrlEncodeUnicode()將多國語言文字轉成的%unnnn格式,對應的是JavaScript escape()函式的轉碼規則,而escape()從ECMAScript V3起就因無法完善支援多國字元被宣告成過時勿用[參考],應改用encodeURI()或encodeURIComponent()。現有多程式庫、API為保持向前相容或許還能解析,但不保證會繼續支援下去。例如:WebUtility.UrlDeocde()就拿掉了%unnnn解析邏輯:[參考]
// *** Source: alm/tfs_core/Framework/Common/UriUtility/HttpUtility.cs // This specific code was copied from above ASP.NET codebase. // Changes done - Removed the logic to handle %Uxxxx as it is not standards compliant. private static string UrlDecodeInternal(string value, Encoding encoding)
追進HttpUtility原始碼,DownloadString()內部使用Uri物件解析URL字串,處理時也不將"%unnnn"視為單一字元,導致%被轉碼為%25,由以下測試可驗證:
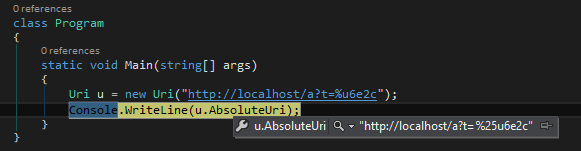
【結論】
- 在JavaScript端,QueryString參數編碼請用encodeURIComponent(),勿再使用escape()。
- 在C#端,請用HttpUtility.UrlEncode()取代HttpUtility.UrlEncodeUnicode()。
Comments
Be the first to post a comment